



Before we dive into GANs, Let’s observe first how machines read images. An image is composed of pixels. Here I have an image I captured of my cat friend.
The image is 3712 pixels by 3712 pixels. Each individual pixel contains data. Since the image is in black and white, each pixel has a value of either 0 (black) or 1 (white).

In greyscale, each pixel now has a value BETWEEN 0.00 (black) and 1.00 (white) (this varies).

In color, each pixel has a red (R), green (G), and blue (B) value (this varies), read by the computer as an array. Here, for example, pixel 1436’s value is (R:122, G:77, B:46).
Because images are composed of data, there is a lot we can do with them. In a simultaneous Digital Imaging course, I manipulated images in Adobe Photoshop: erasing, recoloring, and warping.
When we “Photoshop” things, the program reads the pixel information to alter the data in the pixels. What artists like Van Arman and Anadol do with images, though, is a little bit different from what we are more familiar with in digital imaging.
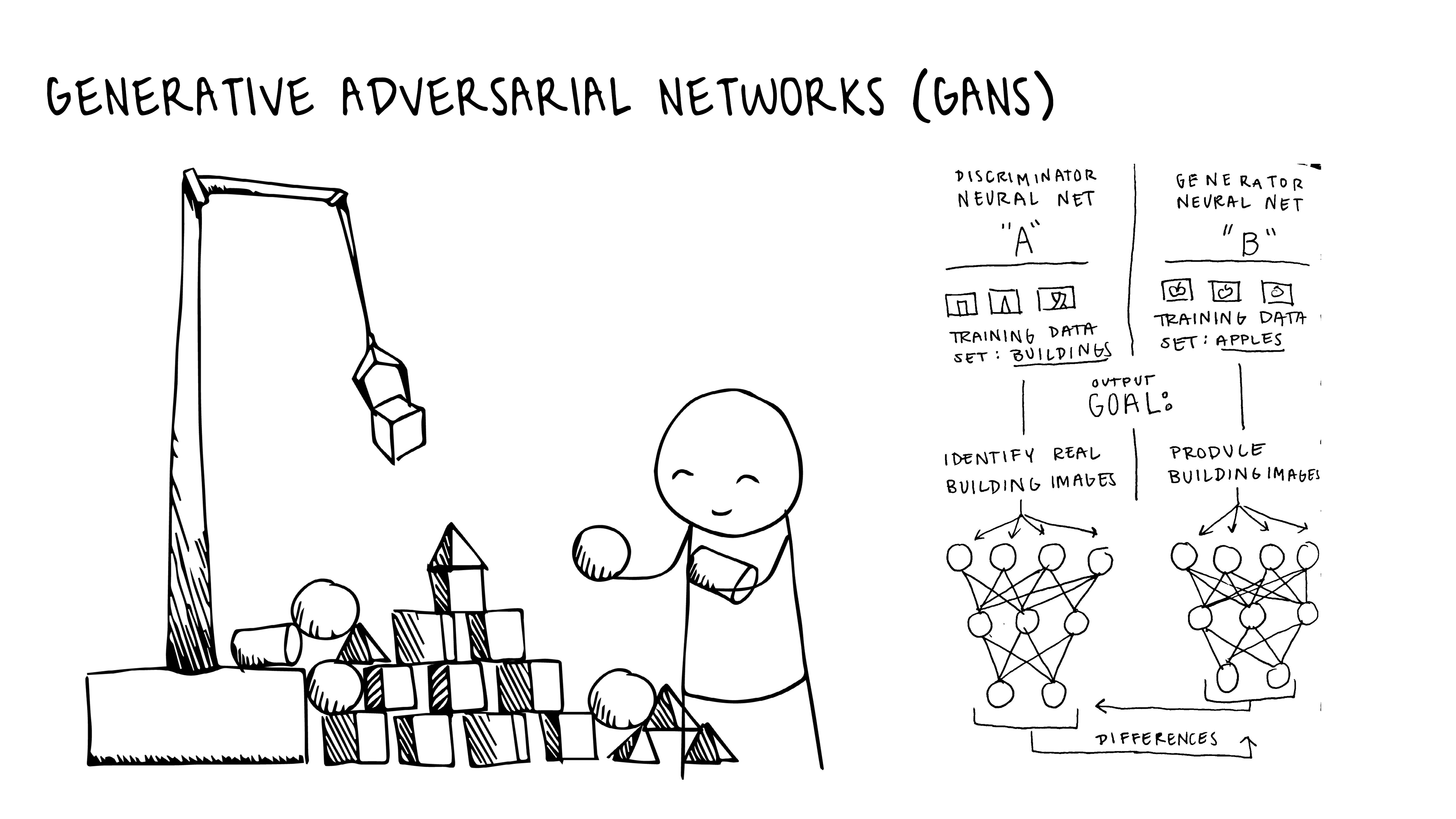
Both artists process their images through Generative Adversarial Networks (GANs). The goal of GANs is to generate completely new content that imitates the original data on which it was trained.
This makes room for endless possibilities. GANs are a reality: machines that can iterate countless floor plans, renders, and facades.
It is important to know that GANs is not the only generative tool artists can use. Everything is specific to a desired task and one program is not necessarily better than the other. Programs like Fractal implement different algorithms to generate iterations. GANs are used for visual imagery, text, and sound. GANs can be trained and curated for your specific project.
Generative Adversarial Networks are composed of two competing Convolutional Neural Networks (CNNs). CNNs are models used for analyzing images.

For the sake of a graphic explanation, let’s say I shrunk our grayscale image here to 32 by 32 pixels.
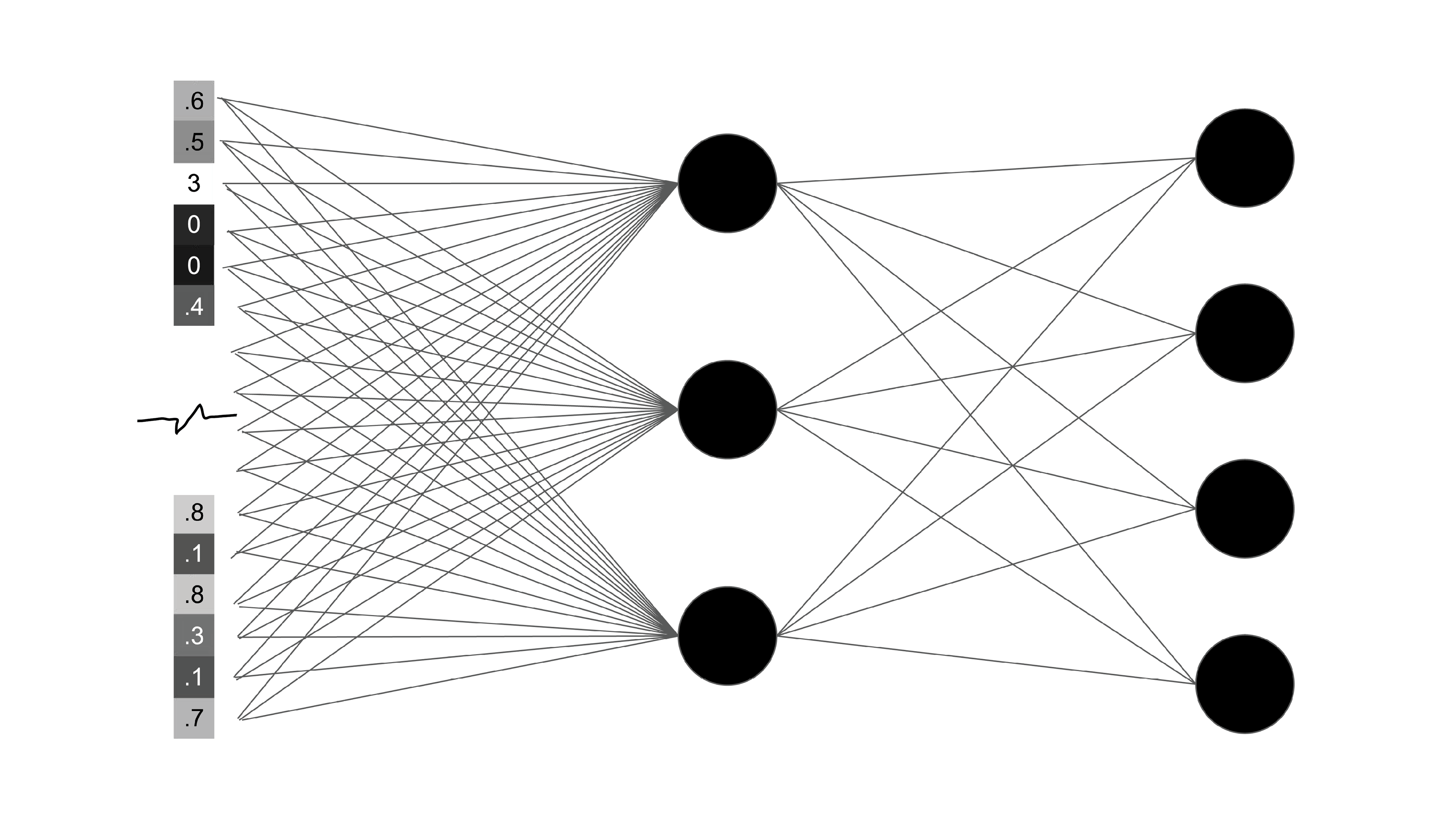
This is how the convolutional neural network begins to read the image, by each pixels’ value. Each pixel is attached along a channel (the line) to a convolutional filter (the circles shown here). Each filter reads the image in a different way (edge detection, segmentation, etc.).
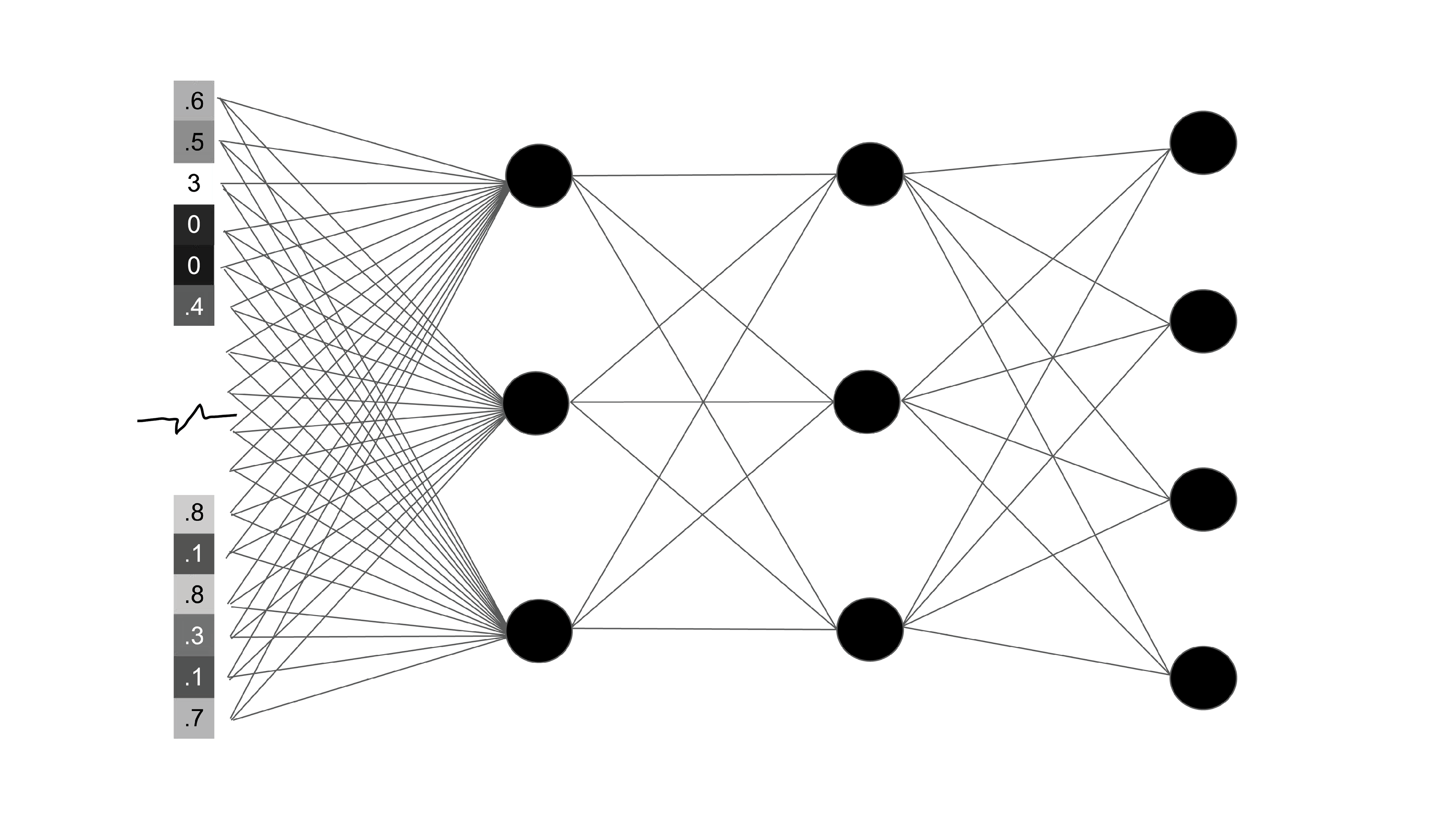
There can be many layers of filters. Deeper layers can even begin to recognize windows, streets, people, etc.. The amount of filters per layer and amount of layers are initially chosen by the programmer. The filters read patterns in an image, but how that is done varies by algorithm, some options are convolving, max pooling, and activation functions (sigmoid function or tanh).
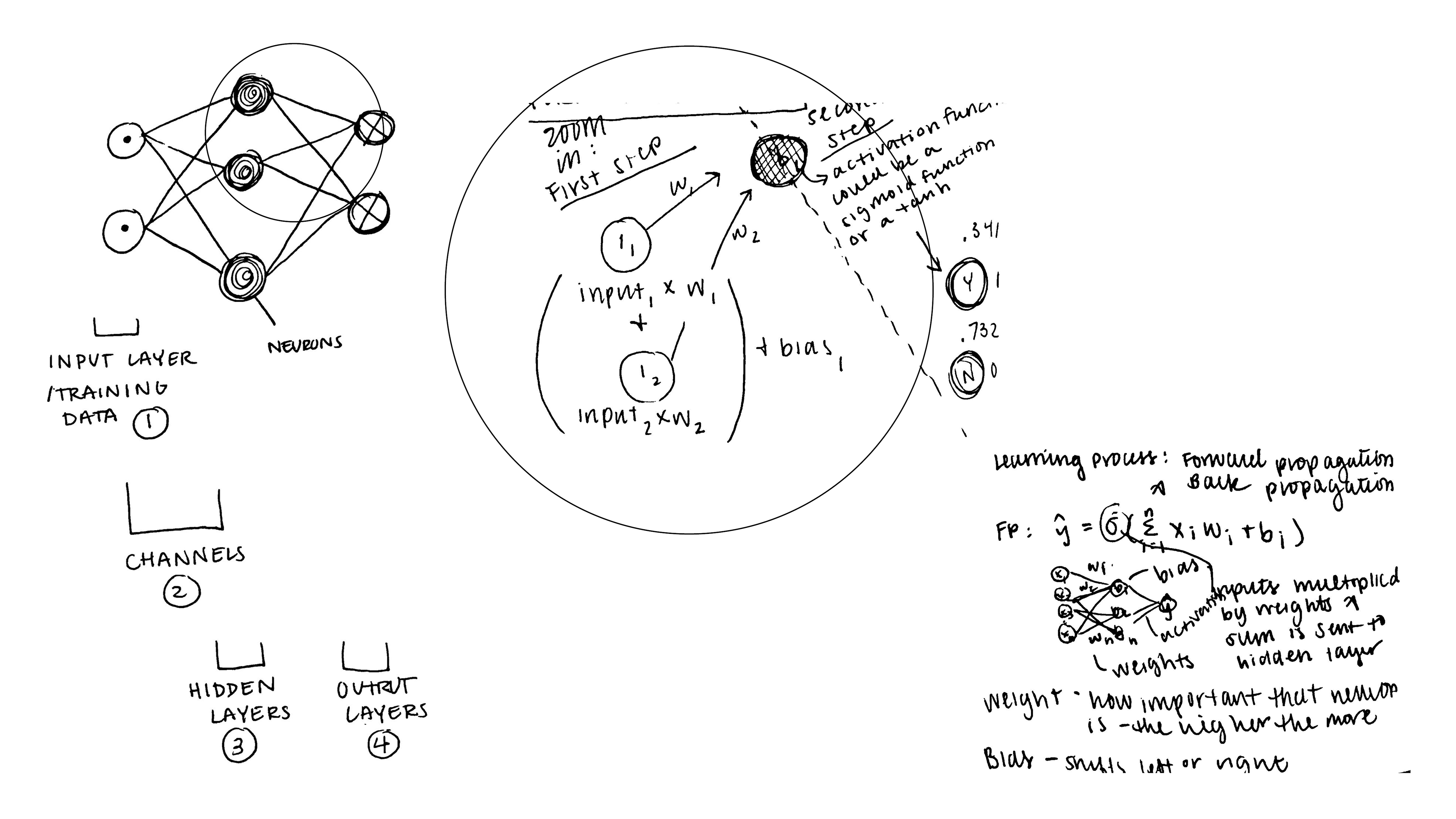
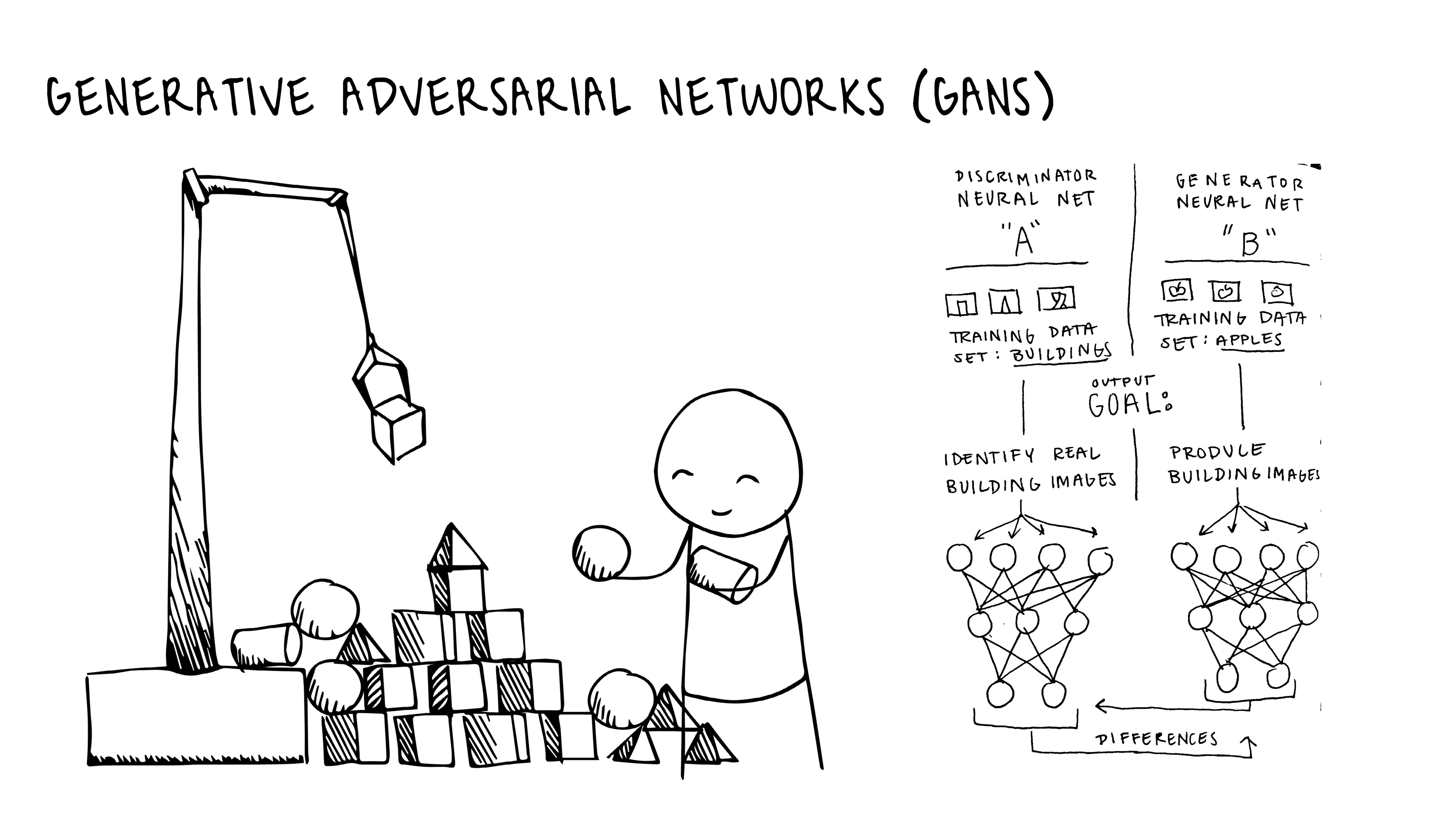
As stated, generative adversarial networks use CNNs. In the name, adversarial stands for the opposing CNNs. In the GAN’s, one of the CNNs compares its output data with the other CNN’s output data.
Okay, I know these are a lot of new words to some. I spent many nights crying over understanding everything. The best way I could comprehend is through metaphor:
You can imagine the first CNN as an art forger (Jerry). Jerry especially wants to forge Picassos. Unfortunately, he has no idea what a Picasso looks like, only that it’s worth money.

The second CNN is a detective (Tom), one that is learning Picasso's work. Tom's special assignment is to determine real Picasso’s from fakes.

Jerry the Art Forger tries to sell his first attempts at recreating Picasso’s, unfortunately, they are just paintings of cheese.

Tom looks at the cheese paintings and says, “these do not look like any Picasso I’ve ever seen, these are fake!” Unfortunately, Tom is also a blabbermouth, and he tells Jerry EXACTLY why they don’t look like Picassos

Realizing what he’s done, Tom returns to his office to study Picassos even better than before.

Simultaneously, Jerry, now knowing the differences between his cheese paintings and Picasso paintings as described by Tom, goes back and gives his forging another go.

Each time Jerry tries to sell his forgeries, they look a little less like cheese and a little more like Picassos.
Tom studies hard to be the biggest expert in Picasso’s but his dang blabbermouth eventually lets Jerry surpass him. Soon (after about a few thousand more cat and mouse chases)...


Jerry can forge Picassos with ease, so much so that Tom can’t tell the real ones from the fake - and neither can Humans.

Okay, so It’s a lot more complicated than this.
We have to take into account Jerry's art skills, and how many Picasso’s could Tom really have access to, to become an expert?
Also, if all Jerry has ever known is cheese, could he even understand what Tom is describing to him, and if so to what extent?
NEXT:
Previous: