



To fully understand GANs and its caveats, I ran my own detective and art forger simulations. Using RunwayML, I could train my own generative adversarial network.
However, instead of Picassos, I fed hundreds of images of cityscapes to the detective, and instead of cheese, hundreds of provided images of mountains to the art forger.
Runway lets the networks run through the images 3000 steps (forgery attempts) at a time. For my final test of the thesis, I ran the GAN for 12,000 steps, here are the results, each frame representing a single image output:
EXPERIMENT 6. Latent Image Walkthrough.
When embarking on the detective and art forger simulations, my end goal was for the final output of images to be photorealistic, perfect Picassos.
Photorealism, for me, was a metric to measure my understanding of GANs. Additionally, photorealism would prove Generative AI’s potential for design iteration.
Unexpectedly, these images elicited a new concept: that it is through the iterative process of machine learning that we can find the human-touch.
Before I analyze the potential of the final outcome, however, let’s first observe why the machine behaved unexpectedly.
EXPERIMENT 1. Latent Image Walkthrough.
INITIAL DATA MATTERS.
Had Tom only had access to 3 Picassos, you couldn’t very well call him an expert, could you? I ran an experiment (above) where I fed the detective CNN fifteen (15) images of buildings, and the forger, hundreds of images of cars.
The results were amusing.
But as you can see, since the forger only had the detective’s notes to go on about what buildings looked like, he could only produce different variations of those few 15 buildings.
RunwayML suggests datasets contain between 500 to 5000 photos.
EXPERIMENT 2. Latent Image Walkthrough.
Using a dataset I compiled, I ran a test (above) with 291 images of Philadelphia, the results (after 6000 steps) were less than satisfactory.
EXPERIMENT 3. Latent Image Walkthrough.
In a different example, I used thousands of images of galaxies for the detective and hundreds of images of mountains for the forger. We see here, that after 3000 runs through, the forger created some pretty realistic galaxy images.
CONTENT MATTERS.
You may be thinking right now, "that’s photorealistic! pretty cool!"
I was too.
But galaxies are easy to forge, pixelly speaking.
Images of galaxies contain no objects, no apparent patterns; just stochastic RGB values dispersed across a square.
There was a game I used to play at summer camp. You had to get your partner to draw the image you have hidden from them without showing it to them nor saying what it is.

Image Courtesy of Gene Kogan.
We do this in CNNs within the filter layers. Filters are a way for CNNs to describe or analyze images. (edge detection, patterns, segmentation).
A limitation with RunwayML I came across was that I could not control how many filters nor layers were used in the CNN.
Image of RunwayML.
The CNNs stemmed from pre-trained models using Transfer Learning.
Different GANs are trained to generate specific image objects. RunwayML hosts StyleGAN. StyleGAN's network analyzes facial features in humans - which is not practical for cityscapes.
Though Transfer Learning did not benefit my specific experiments, it does have its advantages: Quicker run times (since the CNNs don’t have to train initially) and less images are needed in the datasets.
PREPROCESSING MATTERS.
Knowing, however, how the filters work, we can begin to analyze the data sets ourselves. Since we're all experts here now on how CNNs analyze images, let's go back to our pixels:

Looking back at our 3712x3712 image, you can identify it as a cat. Fortunately for you, you don’t have to look at the image pixel by pixel to understand that.
The CNN has to read each 13,778,944 pixels individually, not to mention its in color so that's 3x the amount of information, and depending on the amount of filters, (let’s pretend 12 filters and 3 layers of 12) that’s 23,810,015,232 equations it has to adjust and iterate through.
Worse yet, it does that for thousands of images at a time.
That’s a lot of data.
My laptop crumbles under the pressure of a photoshop file with too many layers, it would quite actually stop working if I ran a GAN experiment of that scale.
In fact, there is a GAN called BigGAN that is capable of incredibly high quality outputs, but the developers needed to utilize 500 GPUs. Since I do not have access to 500 GPUs, I need to preprocess my datasets.

Pre-processing is the act of cultivating your image dataset prior to GANs.
Specific techniques used are gaussian blurring, flipping, shifting, and adjusting brightness and contrast. Resizing is also the most common, because as stated, it is not ideal for the machine to run trillions of bits of data.
RunwayML resizes all images to 512x512 pixels. Creating an equal playing field for the program to read images. Additionally CNNs require all images to be cropped squared. Knowing this preemptively, when collecting images for my dataset, I set the camera to a 1:1 ratio.

After the Philadelphia Dataset (EXPERIMENT 2) didn’t reach my expectations, I resulted to taking more photos around Boston and NYC, as well as compiling old images from my phone; eventually reaching 827 images.
I was scared that this would still not be enough, and thought if I preprocessed them by making mirrored copies I could double the dataset to 1654 images
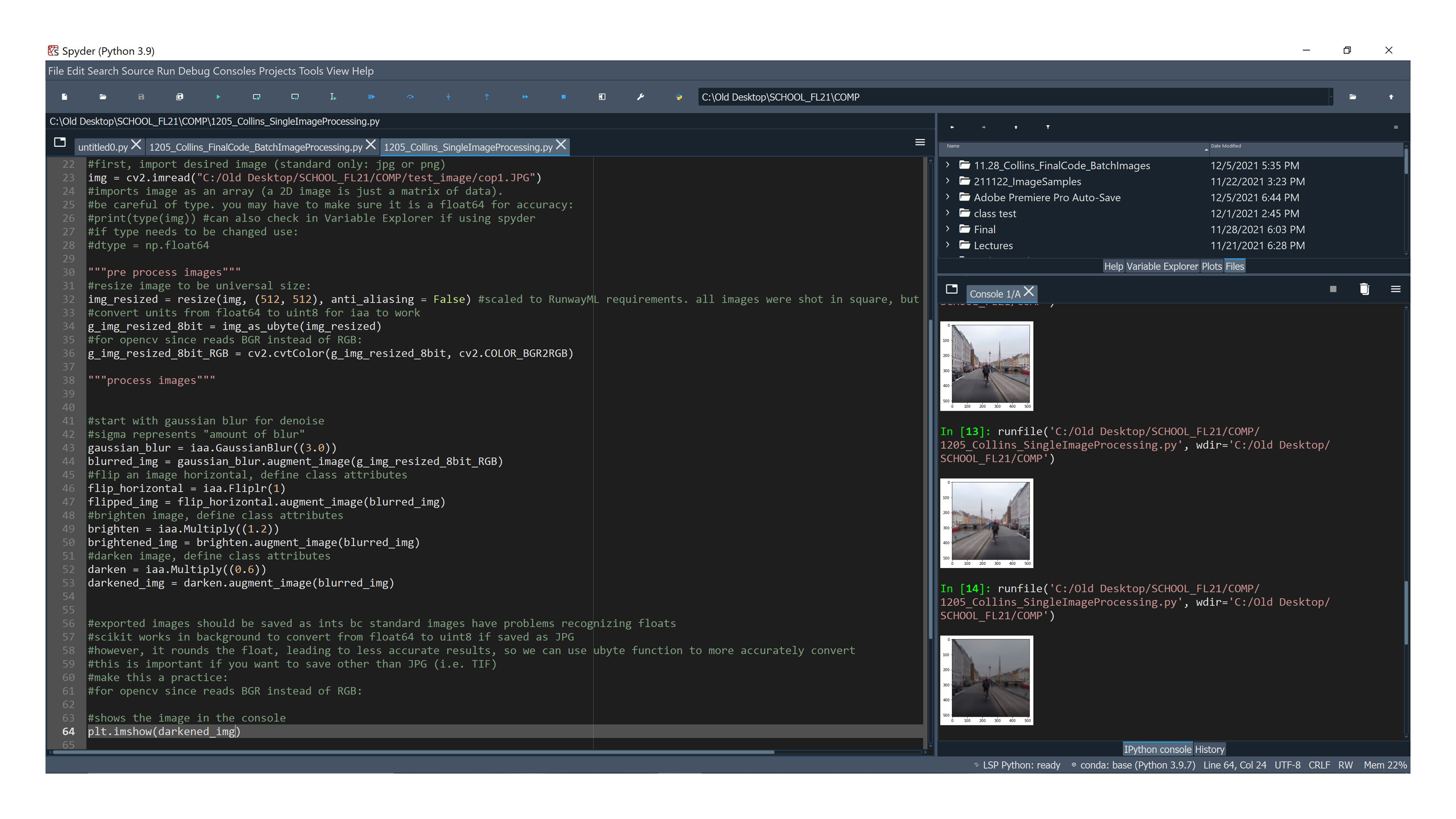
Here arose a new dilemma: it is a tedious process to make copies of and augment each individually. I eventually learned to code my own program* that could augment batches of images for me.
When it came time to augment, I ultimately decided against making copies of all of the images. When preparing datasets, there should be variation (lighting, color, angle).
*You can view a step by step breakdown of the working code here.

I found that I had significantly more images of Philadelphia than any other city. Not wanting significant bias in my generated images, I made copies of all images but those of Philadelphia.
My final data consisted of 1342 images. I was ready to start the training process. Or so I thought.
RUNWAYML LIMITATIONS
As stated before, RunwayML trains for 3000 steps at a time. What I haven’t mentioned is that RunwayML charges per step. Roughly $15 every 3000 steps. At first this wasn’t a concern*. But, as the Philly dataset failed, training for another 3000 steps started to add up.
Additionally, when the final dataset began to fail, I suspected it was due to the selected “forger'' images of landscapes, so I switched them to images of buildings. To be cautious with my money, I resorted to doing my own predictive calculations.
*At the time of this experiment I was a broke college student. Cost is also a viable concern in the field of AI that should be a considered factor when running programs.
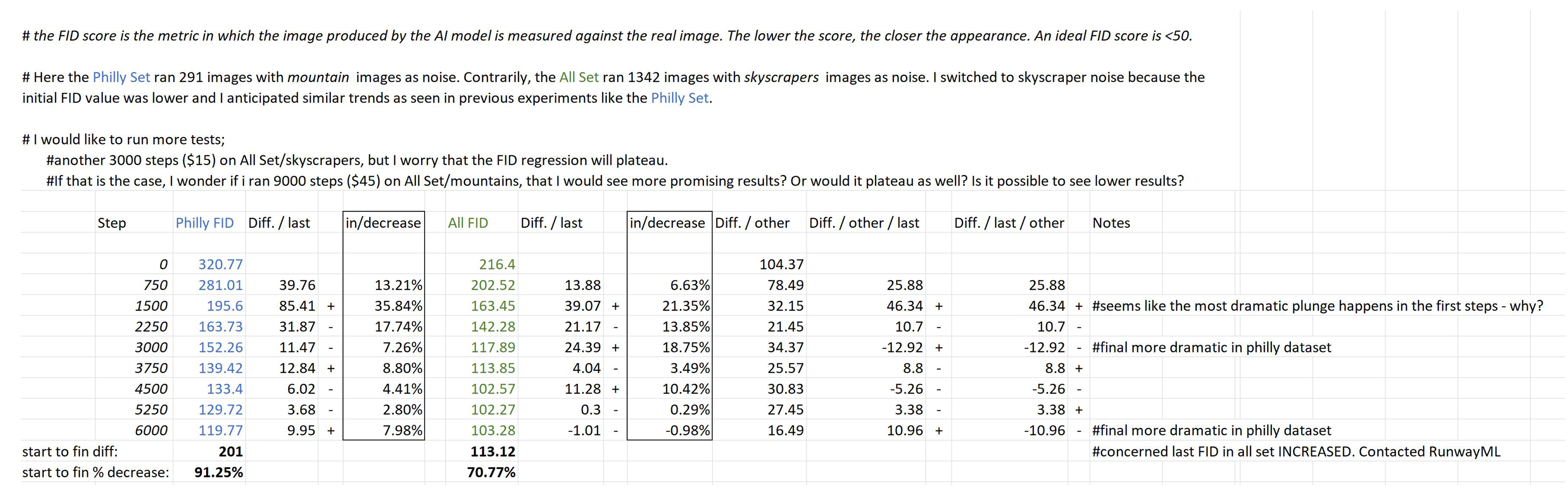
In this chart I analyze output trends following every 250 steps per experiment. I could compare each experiment’s Frechet Inception Difference (FID). The FID score is Runway’s unit of measurement for the visual similarity between the generated images and the original dataset (the lower the score the better).
After each nail-biting 3000 steps, I had to assess if it was worth it to continue the experiment, and analyze why the model might be behaving this way.

Comparing EXPERIMENT 2 (Philadelphia) to EXPERIMENT 6 (All Cities):
At 12,000 steps, the FID score started to increase in EXPERIMENT 6, suggesting the images were becoming less realistic. This behavior was completely unexpected, and not exhibited in any previous experiment.
I can only hypothesize that the behavior I observed towards the end of 12000 steps can be attributed to the type of GAN that RunwayML uses.
StyleGANs is trained specifically on human faces, the filters in the networks look for visual patterns from facial attributes. A face by no means looks like a city. You can even start to see traces of facial edge detection in some of the final images.
It is possible that I could run this experiment thousands more times, the Transfer Learning in this case scenario is working against me, and definitely not in the long run. It is also possible that I could run the experiment another 3000 steps and the FID score plummets. Suggesting the networks unlearned pre-trained patterns of faces, and are starting to find patterns in cityscapes.*
*I recently ran EXPERIMENT 6 an additional 3000 steps (reaching 15000 total steps) and the FID score increased again. More research needed to dissect this behavior.
CONCLUSION.
EXPERIMENT 4. Latent Image Walkthrough.
Johann Wolfgang von Goethe examines art in three phases:
“What was the goal?
Was it achieved?
And was it worth doing?”
EXPERIMENT 5. Latent Image Walkthrough.
Despite my photorealistic expectations, my initial goal for this project was to learn about and produce a final project on Artificial Intelligence and Machine Learning as it relates to design.
That goal was achieved.
But was it worth doing?
Yes, from the perspective that I will utilize what I have learned in the future and will continue to learn about these concepts as they relate to design.
EXPERIMENT 2. Process Image Walkthrough.
There are still questions I have unanswered, like: “could AI replace designers?” and "How can we implement these programs in the education system?" There are many experiments I want to and can run, but simply ran out of time (and money) to.
However, this is not just a semester project: It is a new-found passion of mine that I will pursue going into my professional career.
EXPERIMENT 7. Latent Image Walkthrough.
I am confident in what I have learned and produced in this project. What I initially considered a failure, I now believe holds more value than if the program behaved as expected.
The abstract nature of the images exudes humanity, a concept still debated by professionals in the field, like Refik Anadol. We are all so focused on the outcome of AI behaving as super-humans, that we ignore the process of AI behaving as human.